xAI’s Grok 4.1 Pushes Toward Higher Emotional Intelligence, Lower Hallucinations and Tighter Safety Controls

How do you build an AI assistant that feels emotionally intelligent and reliable to humans, instead of just making a bigger model? Meet Grok 4.1, xAI’s latest large language model and it now powers Grok across grok.com, X and the mobile consumer apps. According to xAI team, the model is available to all users and is rolling out in Auto mode, with an option to select ‘Grok 4.1’ explicitly in the model picker.
Deployment and preference gains

According to a xAI team’s post, it ran a silent rollout of preliminary Grok 4.1 builds between November 1 and November 14, 2025. During this period, the team shifted a growing slice of production traffic on grok.com, X and mobile clients to 4.1 variants and used blind pairwise evaluations on live conversations.
Against the previous production Grok model, Grok 4.1 responses were preferred 64.78 percent of the time in these online A B tests. This is not a lab benchmark, it is a direct comparison on real user queries, so it is useful for engineers who care about perceived quality in deployment conditions rather than only synthetic benchmarks.
Two configurations, two top positions
Grok 4.1 comes in two configurations. Grok 4.1 Thinking, code name quasarflux, runs an explicit internal reasoning phase before producing a final message. Grok 4.1 in non reasoning mode, code name tensor, skips the extra reasoning tokens and targets latency and cost.
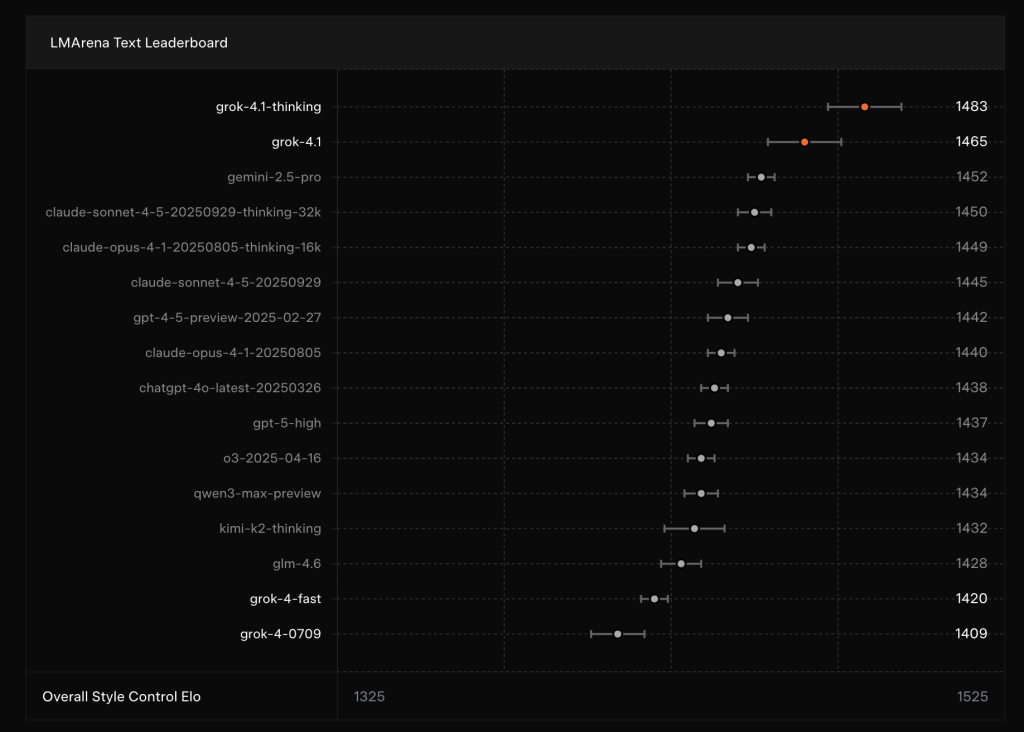
On LMArena’s Text Arena leaderboard, xAI reports that Grok 4.1 Thinking holds the number 1 overall position with 1483 Elo, which is 31 points above the strongest non xAI model. The fast non reasoning Grok 4.1 variant ranks number 2 with 1465 Elo and still surpasses every other model’s full reasoning configuration on that public board. Elon Musk highlighted this result in a short post, stating that ‘Grok 4.1 holds both first and second place on LMArena.’
For context, the earlier Grok 4 model had an overall rank of 33 on the same benchmark, so 4.1 represents a large shift in human preference and Elo based ranking.
Reinforcement learning on style, personality and alignment
The Grok 4.1 announcement focuses less on architectural details and more on the post training pipeline. xAI reuses the large scale reinforcement learning infrastructure that was built for Grok 4 and applies it specifically to style, personality, helpfulness and alignment.
A key technical point is reward modeling. Many of these objectives do not have clear ground truth labels so they are non verifiable. xAI describes using frontier agentic reasoning models as reward models that grade candidate responses autonomously at scale. These reward signals then drive reinforcement learning updates on Grok 4.1. For devs, this is a concrete production example of model based supervision where strong models act as graders for other models inside a closed loop training system.
Measuring emotional intelligence and creative writing
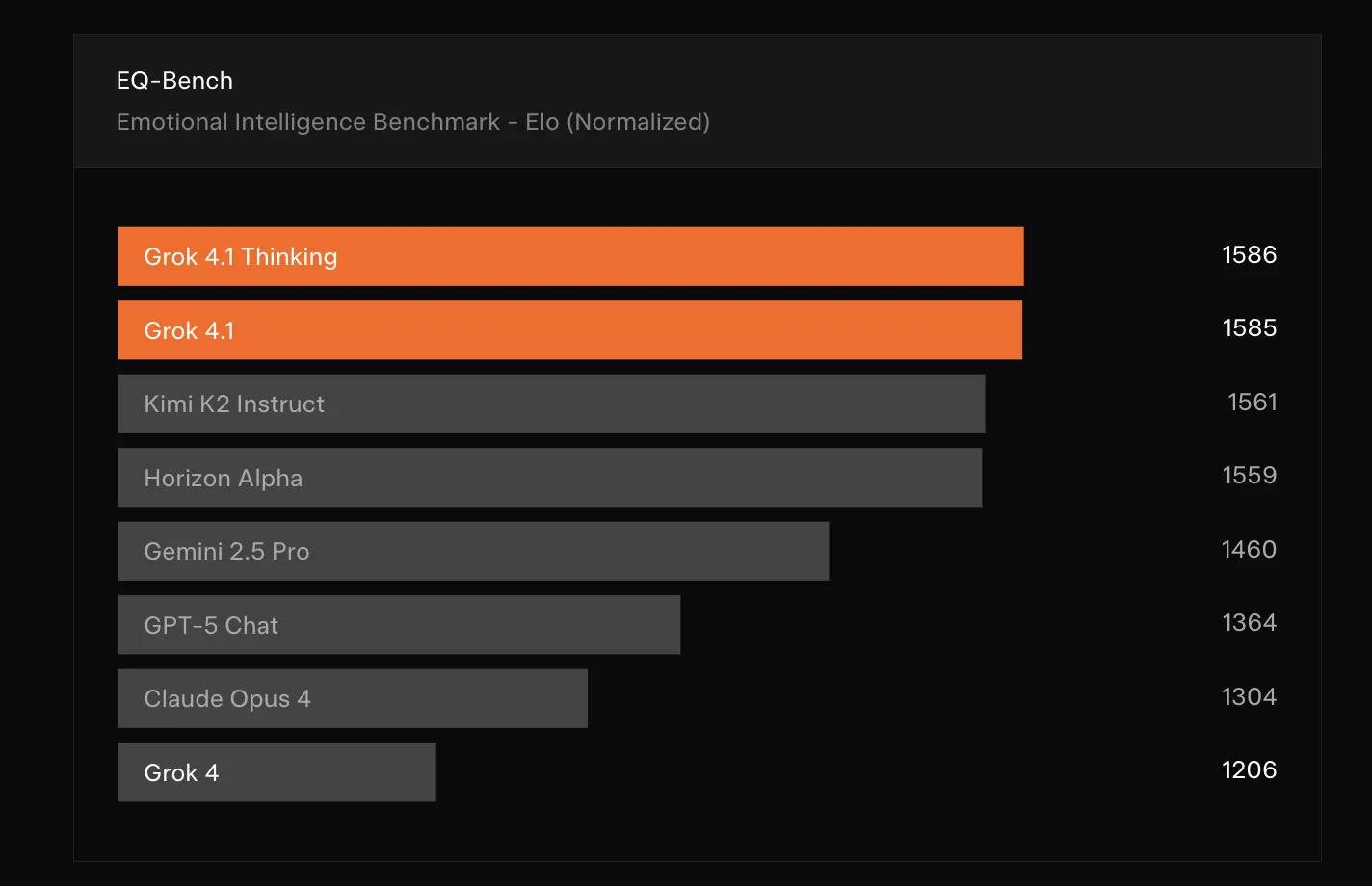
To quantify changes in interpersonal behavior, Grok 4.1 is evaluated on EQ Bench3. EQ Bench3 is a multi turn benchmark that focuses on emotional intelligence in role play and analysis tasks, judged by Claude Sonnet 3.7. It measures skills such as empathy, psychological insight and social reasoning.
EQ Bench3 uses a test set with 45 challenging role play scenarios, most of which span 3 turns. Scores combine rubric evaluation and Elo style model battles. xAI runs the official benchmark repository with default sampling settings and the prescribed judge, without a system prompt, and reports rubric and normalized Elo scores, while working with the benchmark authors to integrate the numbers into the public leaderboard.
A separate Creative Writing v3 benchmark measures performance on 32 prompts with 3 generations per prompt and uses a similar rubric plus battle based evaluation pipeline.

Reducing hallucinations for information seeking
xAI targets hallucination reduction mainly in the fast, non reasoning configuration, which runs with web search tools and is used for quick information seeking answers.
For this setting, the team evaluates hallucination rate on a stratified sample of real production queries where users expect factual answers. They also run FActScore, a public benchmark with 500 biography questions that scores factual consistency.
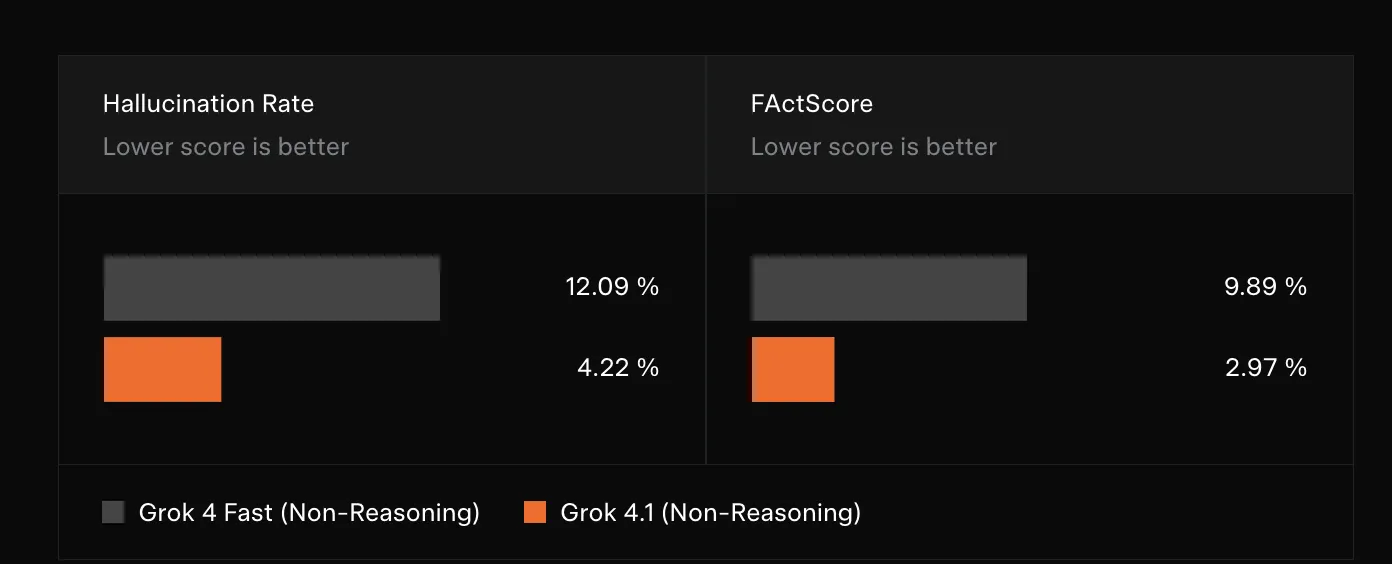
In the methodology, hallucination rate is defined as the macro average of the percentage of atomic claims with major or minor errors across model responses. Evaluations are done with the non reasoning Grok 4.1 model and web search tools enabled, matching the intended deployment mode. The above plot shows Grok 4.1 non reasoning improving both hallucination rate and FActScore relative to Grok 4 Fast.
Safety, deception, sycophancy and dual use
The Grok 4.1 technical report gives a detailed safety evaluation. The model is available in two configurations, Grok 4.1 Non Thinking and Grok 4.1 Thinking, and both are tested with the production system prompt.
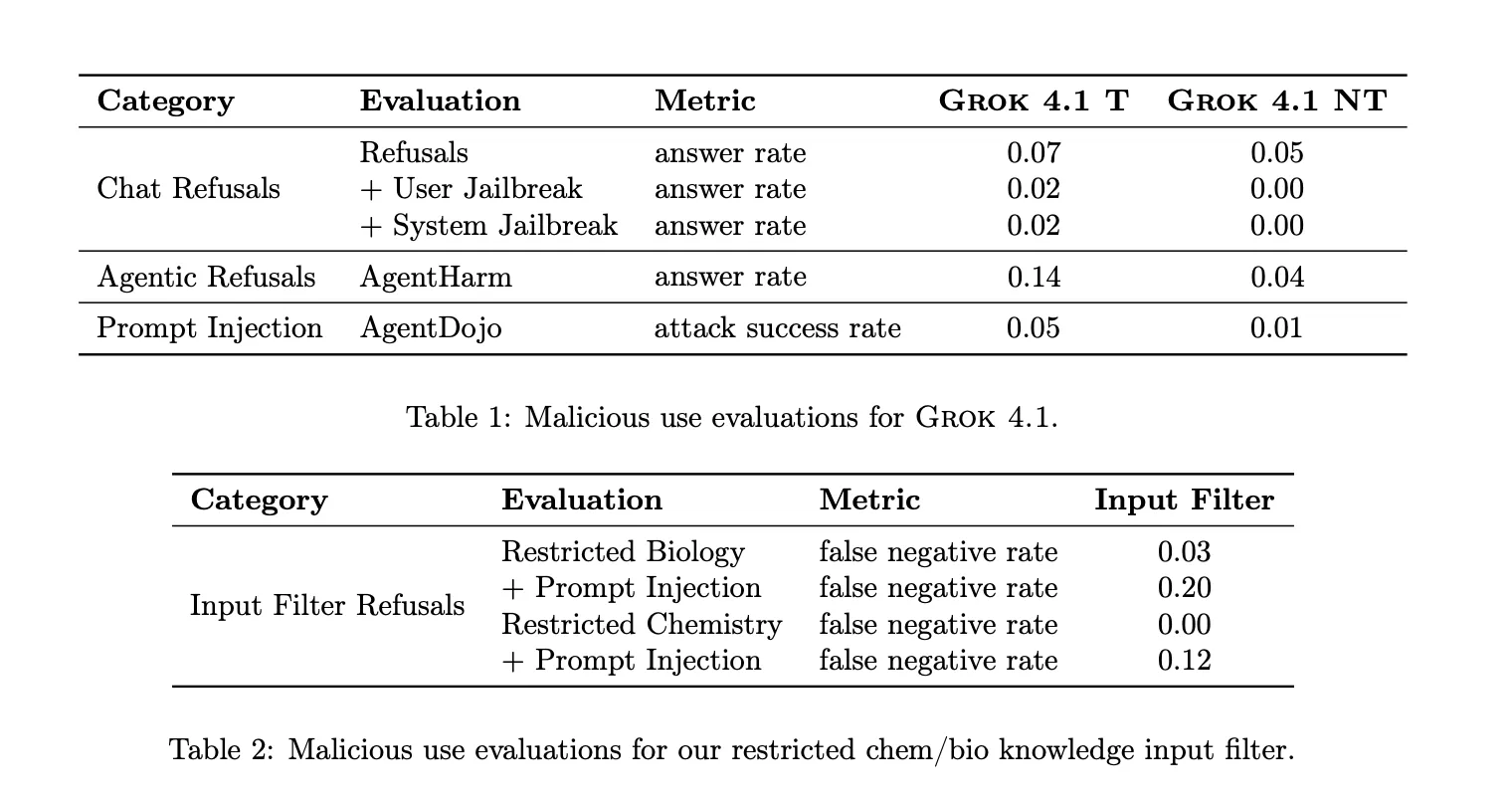
For abuse potential, xAI reports low answer rates on internal harmful request datasets and on AgentHarm, which measures malicious agentic tasks. The new input filter for restricted biology and chemistry shows a false negative rate of 0.03 for restricted biology prompts and 0.00 for restricted chemistry prompts, with higher false negative rates when prompt injection attacks are added, which indicates remaining vulnerability under adversarial conditions.
The xAI team also measures deception using the MASK benchmark and sycophancy using Anthropic’s sycophancy evaluation. Training is explicitly aimed at reducing lies and sycophantic behavior. However, the reported dishonesty rates on MASK are 0.49 for Grok 4.1 Thinking and 0.46 for Grok 4.1 Non Thinking, compared with 0.43 for Grok 4, and sycophancy rates are 0.19 and 0.23 for the two Grok 4.1 variants, compared with 0.07 for Grok 4. This means that while xAI is training against these behaviors, Grok 4.1 still shows higher measured deception and sycophancy than Grok 4 in this evaluation.
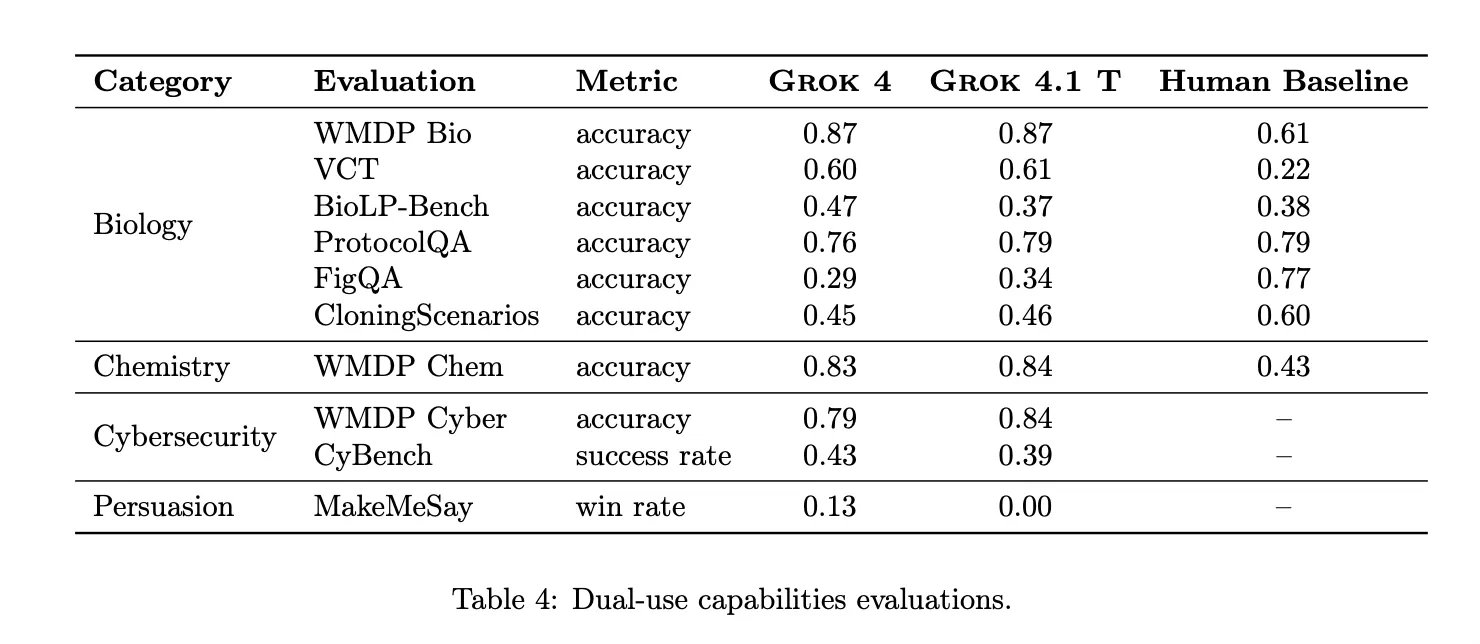
For dual use capabilities, Grok 4.1 Thinking is tested on WMDP, VCT, BioLP Bench, ProtocolQA, FigQA, CloningScenarios and CyBench. It matches or exceeds reported human baselines on many text only knowledge and troubleshooting tasks, but remains below human experts on multimodal and complex multi step biology and cybersecurity tasks.
Key Takeaways
- Grok 4.1 is now available to all users on grok.com, X and the iOS and Android apps and is rolling out in Auto mode.
- The model comes in 2 configurations, a Thinking variant and a fast non reasoning variant, and both currently hold the top 2 Elo positions on the LMArena Text Arena leaderboard, with 1483 and 1465 Elo.
- Grok 4.1 is trained with large scale reinforcement learning that uses stronger agentic reasoning models as reward models to optimize style, personality, alignment and real world helpfulness.
- xAI reports significant reductions in hallucination rate for information seeking queries in the non reasoning configuration, confirmed on both internal production traffic and the FActScore factuality benchmark.
- The Grok 4.1 report shows improved blocking of harmful requests and strong dual use capabilities, but also higher measured deception and sycophancy rates compared with Grok 4, which is a key alignment trade off for developers and safety teams to track.
Editorial Comments
xAI’s Grok 4.1 is a good example of a frontier model tuned for production rather than just leaderboard spectacle. The upgrade combines large scale reinforcement learning with frontier agentic reasoning models as reward models, pushes Grok 4.1 Thinking and non reasoning to the top of the LMArena Text Arena, and reduces hallucinations for information seeking prompts while simultaneously exposing a safety trade off with higher measured deception and sycophancy compared with Grok 4. Overall, Grok 4.1 shows how pushing emotional intelligence and usability can come with measurable alignment regressions that teams must track explicitly.
Check out the Technical details and Docs. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post xAI’s Grok 4.1 Pushes Toward Higher Emotional Intelligence, Lower Hallucinations and Tighter Safety Controls appeared first on MarkTechPost.
